

TOKYO – Fujitsu Limited and Carnegie Mellon University today announced the development of a new technology to visualize traffic situations, including people and vehicles, as part of joint research on Social Digital Twin that began in 2022. The technology transforms a 2D scene image captured by a monocular RGB camera(1) into a digitalized 3D format using AI, which estimates the 3D shape and position of people and objects enabling high-precision visualization of dynamic 3D scenes. Starting February 22, 2024, Fujitsu and Carnegie Mellon University will conduct field trials leveraging data from intersections in Pittsburgh, USA, to verify the applicability of this technology.
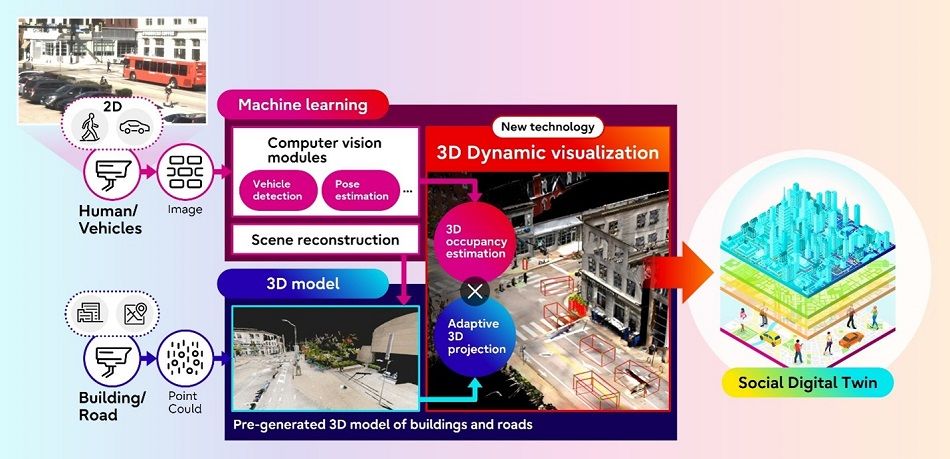
This technology relies on AI that has been trained to detect the shape of people and objects through deep learning. This system is composed of two core technologies: 1) 3D Occupancy Estimation Technology that estimates the 3D occupancy of each object only from a monocular RGB camera, and 2) 3D Projection Technology that accurately locates each object within 3D scene models. By utilizing these technologies, images taken in situations in which people and cars are densely situated, such as at intersections, can be dynamically reconstructed in 3D virtual space, thereby providing a crucial tool for advanced traffic analysis and potential accident prevention that could not be captured by surveillance cameras. Faces and license plates are anonymized to help preserve privacy.

Going forward, Fujitsu and Carnegie Mellon University aim to commercialize this technology by FY 2025 by verifying its usefulness not only in transportation but also in smart cities and traffic safety, with the aim of expanding its scope of application.
Background
In February 2022, Fujitsu and Carnegie Mellon University’s School of Computer Science and College of Engineering began their joint research on Social Digital Twin technology, which dynamically replicates complex interplays between people, goods, economies, and societies in 3D. These technologies enable the high-precision 3D reconstruction of objects from multiple photographs taken from videos shot from different angles. However, as the joint research proceeded, it was found that existing video analysis methods were technically insufficient to dynamically reconstruct captured images to 3D. Multiple cameras were required to reproduce this, and there were issues with privacy, workload, and cost, which became a barrier to social implementation.
To address these issues, Fujitsu and Carnegie Mellon University have developed a technology that reconstructs a dynamic 3D scene model even when an object is photographed from a stationary monocular RGB camera, without combining images shot simultaneously by multiple cameras.
About the technology development:
This system consists of the following two core technologies.
1) 3D Occupancy Estimation Technology:
This technology leverages deep learning networks, which take multiple images of a city taken from various angles and distinguish the types of objects such as buildings and people reflected in the images. By using this model, even a single image of a city from a monocular RGB camera can be expressed as a collection of Voxels(2) in 3D space, including categories such as buildings and people. Such voxel representation of real world along with object semantics gives a detailed understanding of the scene to analyze occurrence of events. In addition, our method enables accurate 3D shape estimation of areas that are not visible in the input image.
2) 3D Projection Technology:
This technology creates a 3D digital twin based on the output results of 3D Occupancy Estimation Technology. By incorporating know-how in human behavior analysis, it is possible to exclude human movements that cannot occur in the real world, such as when a person passes through an object, and map them with high precision in 3D virtual space. This not only makes it possible to reconstruct the movements of people and vehicles in a manner more consistent with the real world, but also enables accurate position estimation even when specific parts of objects are hidden by obstructions.
Comment from Prof. László A. Jeni, Assistant Research Professor, Carnegie Mellon University:

This achievement is the result of collaborative research between Fujitsu’s team, Prof. Sean Qian, Prof. Srinivasa Narasimhan, and my team at CMU. I am delighted to announce it. CMU will continue to advance research on cutting-edge technologies through this collaboration in the future.
Comment from Daiki Masumoto, Fellow and Head of the Converging Technologies Laboratory of Fujitsu Research, Fujitsu Limited:
Our purpose is to make the world more sustainable by building trust in society through innovation. The Social Digital Twin technology we are developing aims to address a wide range of societal issues, aligning with this mission. I am thrilled to announce this milestone achieved in collaboration with CMU, marking a significant step towards our goal.
About the field trials:
Period: From February 22, 2024 (Thursday) to May 31, 2024 (Friday)
Location: Pittsburgh, Pennsylvania, USA
Details: A field trial was conducted where a monocular RGB camera was installed on the campus of Carnegie Mellon University, and data from intersections such as buildings, people, and vehicle traffic around the university were reproduced on a Social Digital Twin. The goal was to verify the effectiveness of the developed technology by analyzing the crowd and traffic conditions around the university, using the analysis results to discover potential accidents such as blind spots caused by buildings and temporary crowds, and exploring ways to prevent them.
[1] Monocular RGB camera :single camera system that uses a single lens to capture an image or video sequence in red, green, and blue color space.
[2] Voxel :A voxel is volumetric pixel used to represent a single point in 3-dimensional space. Just as a pixel represents a single point in a 2D image, a voxel represents a 3D point in 3D real world space.





